QuestDB vs. InfluxDB
Looking for peak time-series? Amplify ingestion and query speeds and significantly reduce infrastructure costs and complexity.

QuestDB's remarkable performance is evident through significantly faster query response times and outstanding real-time data ingestion. Deployment and maintenance of QuestDB proved to be trivial with literally zero production hiccups for over a year now.
Simply the fastest time-series database
Highest cardinality? Check
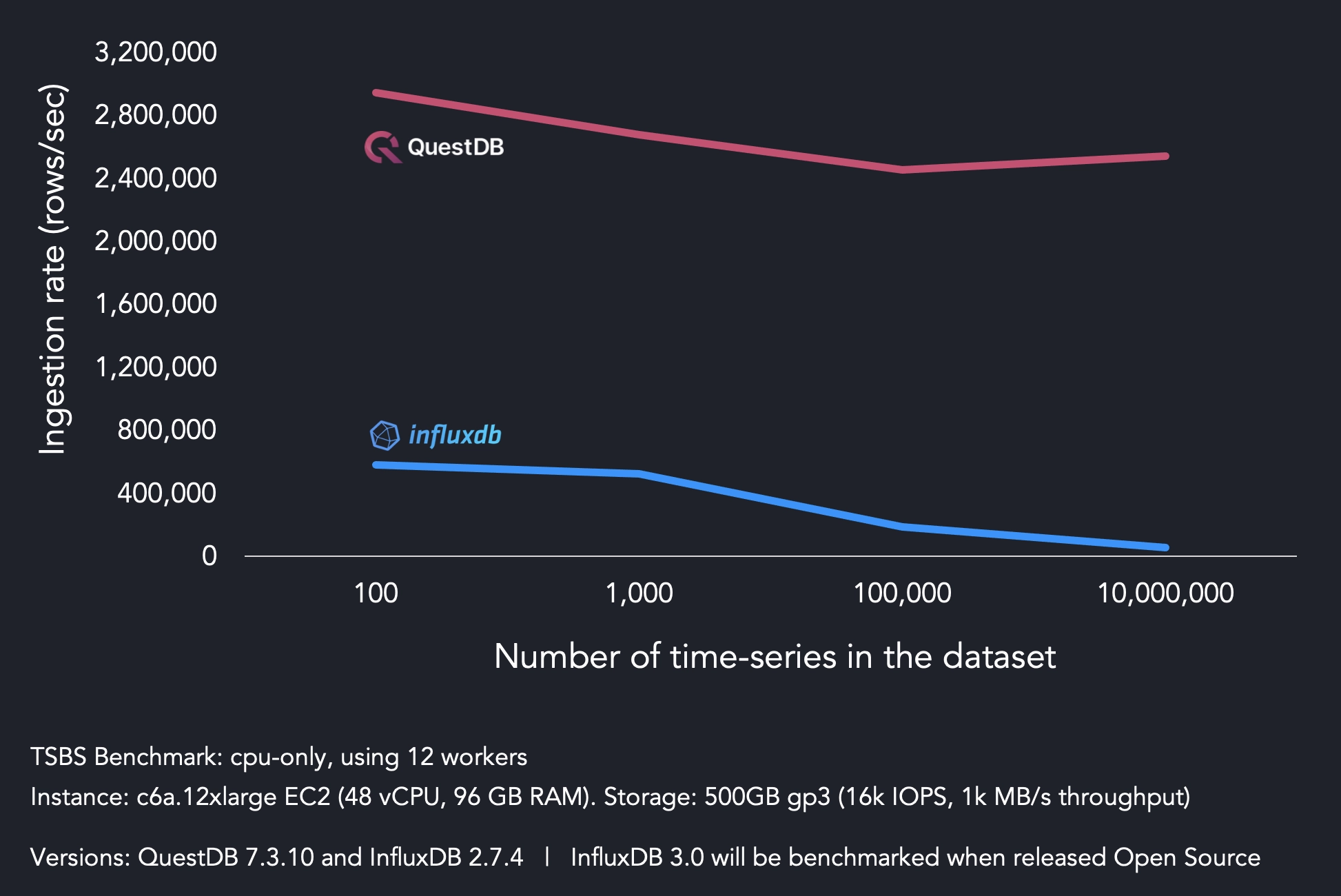
QuestDB significantly outpaces InfluxDB in pure performance. Ingest speeds are 5-12x faster, while more complex queries can see orders of magnitude improvement. Overcome infrastructure bottlenecks and break free from cardinality limits. Bring all your unique values!
Try the live demo
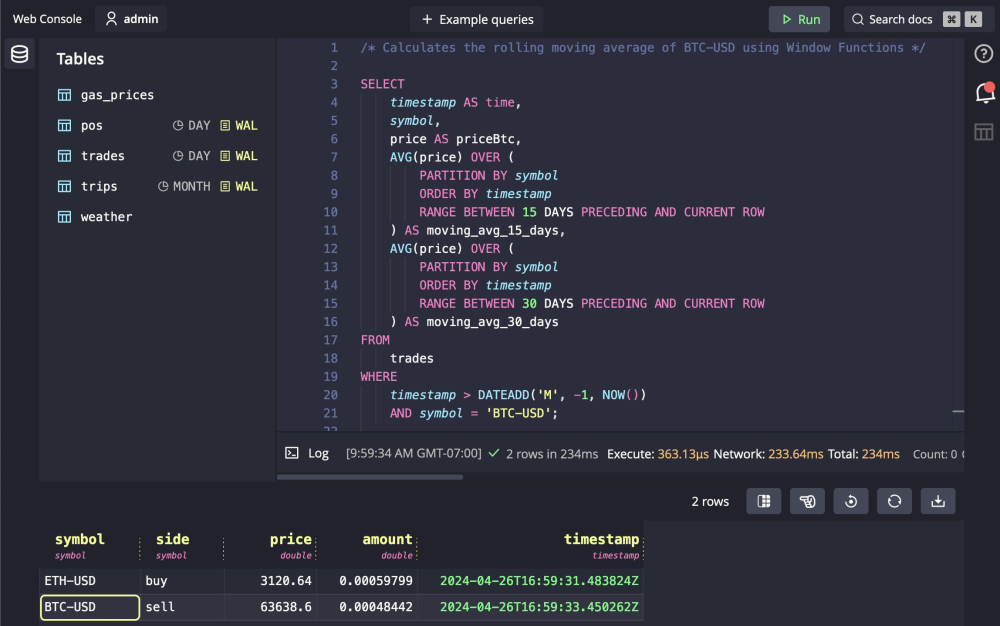
Query over 2 billion rows in milliseconds in the QuestDB Web Console using SQL
Try QuestDB demo in your browser
No DSL required. Enjoy simple SQL.
Reduce complexity and accelerate time-to-value.
Downsample data
Aggregate data into one-minute intervals, reduce the granularity and size of the dataset for efficiency.
Flux
from(bucket: "example-bucket") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "cpu" and r.cpu == "cpu-total" ) |> aggregateWindow(every: 1m, fn: mean)QuestDB
SELECT timestamp, avg(cpu), avg(cpu-total)FROM 'example-bucket'WHERE timestamp > dateadd('h', -1, now())SAMPLE BY 1m;ASOF Joins
Join two tables and get a column from each table where the timestamp matches.
Flux
f1 = from(bucket: "example-bucket-1") |> range(start: "-1h") |> filter(fn: (r) => r._field == "f1") |> drop(columns: "_measurement")
f2 = from(bucket: "example-bucket-2") |> range(start: "-1h") |> filter(fn: (r) => r._field == "f2") |> drop(columns: "_measurement")
union(tables: [f1, f2]) |> pivot( rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value" )QuestDB
SELECT a.timestamp, f1, b.timestamp, f2FROM 'example-table-1' aASOF JOIN 'example-table-2' b;QuestDB was our choice for real time data due to high performance, open source, high flexibility and great support. Performance was significantly better than the competition and we believe that QuestDB will become market leading.
// QuestDB Rust clientuse questdb::{Result,ingress::{Sender,Buffer,TimestampNanos}};fn main() -> Result<()> {let mut sender = Sender::from_conf("http::addr=localhost:9000;")?;let mut buffer = Buffer::new();buffer.table("sensors")?.symbol("id", "toronto1")?.column_f64("temperature", 20.0)?.column_i64("humidity", 50)?.at(TimestampNanos::now())?;sender.flush(&mut buffer)?;Ok(())}
Full ILP compatibility
One string away from top performance
QuestDB supports the InfluxDB Line Protocol (ILP). Apply first-party ILP via the official QuestDB clients. Top performance, useful feedback and clear docs. Upgrade your ingress with a string change. Well documented clients are available for Java, Go, Python, Rust, .NET and Node.js, and more.

InfluxDB could not deal with the shape of our data, which includes wide tables with thousands of column. Instead, we could ingest this data flawlessly into QuestDB, and then query it with SQL easily.
Apache 2.0 plus Enterprise
Always open source, or Enterprise
Open source under Apache 2.0. Enterprise for premium features like distributed clusters, role-based access control, support SLAs and more. That's it. Clear and simple!

We switched from InfluxDB to QuestDB to get queries that are on average 300x faster utilizing 1/4 of the hardware, without ever overtaxing our servers.
Future roadmap, from our community
Blazing speed, bright future
Globally distributed, hyper-fast next generation database

- Open formats
- Leverages existing open formats. No vendor lock-in.
- Apache Parquet
- Enhanced compression and encoding, for ingress or egress.
- Super read/write
- In-memory processing via Apache Arrow, combined with SQL.
- Full stream
- Stream market data in from feeds or sensors, apply Parquet on read
- Direct to Parquet?
- Bypass QuestDB ingest, query Parquet directly from the object store
- Versatile ecosystem
- Diverse clients connect to your data, app, AI and ML frameworks